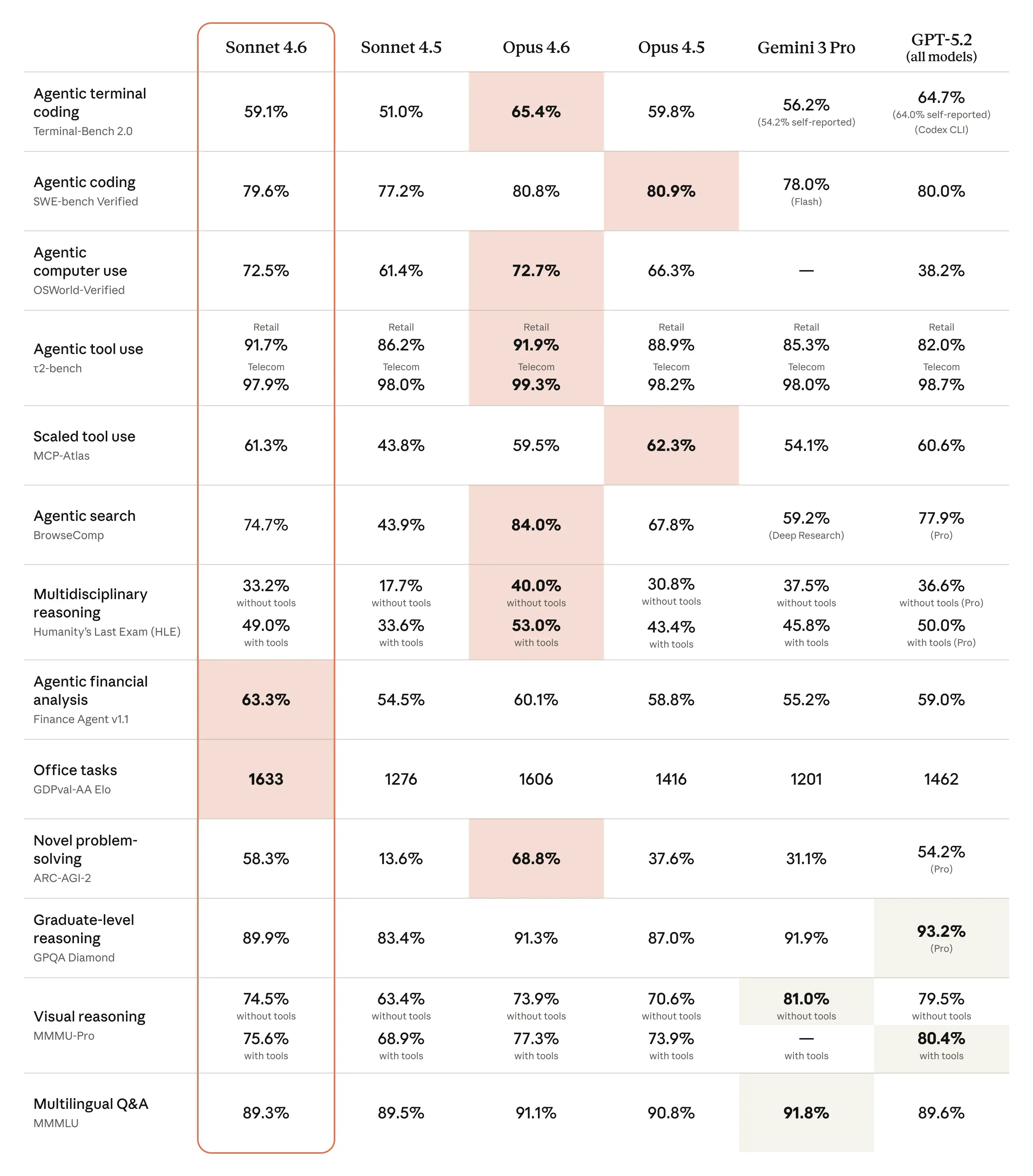
https://artificialanalysis.ai indicates that sonnect 4.6 beats opus 4.6 on GDPval-AA, Terminal-Bench Hard, AA Long context Reasoning, IFBench.
see: https://artificialanalysis.ai/?models=claude-sonnet-4-6%2Ccl...
https://www.anthropic.com/_next/image?url=https%3A%2F%2Fwww-...
basically 9/13 are very close
{kind=link}